故障推理引擎加持下的告警理念转变
在故障推理引擎加持下如何实现减少告警,做到精准告警
在 Kindling-OriginX 中只有业务请求受到故障影响才会告警,其他时候指标异常、故障都不会告警。为什么要这样设计呢?主要有以下几个主要原因:
- 传统基于指标的告警:误报与漏报的告警非常多,信噪比非常高,会导致运维人员疲劳而忽略了真实的告警,而延误了告警的处理时间,导致严重的故障后果。
- 基于指标的告警的本质是基于经验的设计告警的大杂烩,每个运维团队的告警都是在不断采坑中,不断完善指标告警,但是这个告警处理依赖于设计这个规则的人。但是人员是流动的,这些经验往往不会及时调整,而是不断累积,形成一个庞大而复杂告警体系。
- 庞大而复杂的告警体系中,多指标是在技术上其实关联的,但是由于指标告警的时候是没有理解其内在关联性,一旦真实故障产生,各种误告警会不断产生,引发告警风暴。
- 告警还有一个作用,就是当业务发生真实告警之时,期望指标告警能够为故�障定位提供指导,但是没有专家经验治理的情况下,会产生告警太多的困惑,到底哪个是因,哪个是果不清楚,该往哪里排查也不清楚。
在Kindling-Originx中不需要传统告警提示排查方向
Kindling-Originx的核心能力就是故障根因推导,能够分钟级甚至秒级出故障报告,直接给出故障定位的初因。在这种情况下,无需配置指标告警来提示根因了,用户直接在故障根因推导的报告中能够得到定位的初因,同时也能够完整查看故障根因推导的过程,看出在整个推导过程中,有哪些指标是异于平常,同时可以通过Grafana大盘去观测更多的相关指标,进一步确认故障根因推导的正确与否。
基于API的SLO告警是Kindling-OriginX的使用入口
为了能够在生产环境中真正完成“1-5-10”,即1 分钟发现-5 分钟处置-10 分钟恢复的目标,通过 Kindling-OriginX 用户只需要设定和关注 API的SLO,并通过 SLO 关注系统状态结合 Kindling-OriginX 精准高效的故障根因分析技术,就能够使用户在极短的时间内响应并解决问题,发现各种隐患。这意味着即使是没有深厚技术背景和强大专家团队的用户也能��够利用 Kindling-OriginX 来达成“1-5-10”目标,大大降低了技术门槛,提升了效率和可靠性。
推荐步骤
- 定义 API SLO (系统默认以历史数据设定)
- 当 SLO 违反时,查看对应时间段所生成的故障报告
- 根据故障报告内的根因分析数据,定位并解决问题,或根据推荐操作启动对应处置方案。
- 针对存疑根因分析结果,查看其详细推导数据与过程。
推荐流程
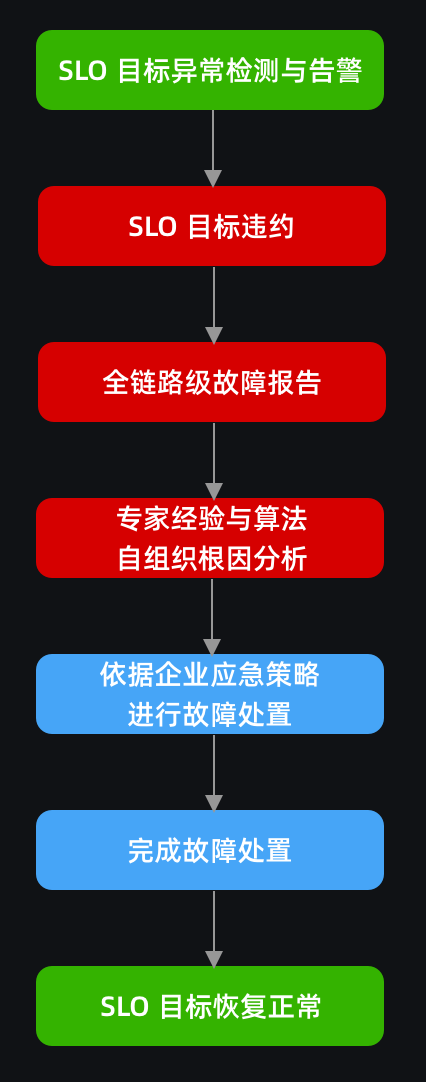
通过 Kindling-OriginX 只需要简单几步就能在不改变组织内原有应急策略和响应流程的情况下,快速提高故障发现速度与故障处理时长,帮助用户找到切实有效的方法落地实践“1-5-10”。
直接使用 Kindling-OriginX 基于SLO业务级别的告警,是否会有滞后性,是否会导致早期潜在故障发展成严重故障?
例子:传统运维视角,配置了JVM内存使用量告警,一旦JVM内存使用量达到一定阀值意味着内存可能存在泄露的可能,JVM内存使用量告警可以及早的请相关人员介入,避免潜在的风险演变成严重的内存OOM问题导致用户在业务接口上延时和错误率上升。
对于所有存在潜在问题发展成严重事故的故障,都会遵循以下的演变规律:
- 初始阶段(无明显影响)
- 比如CPU使用率高:一开始,系统可能有足够的资源来处理增加的负载,所以高CPU使用率不会立即影响业务性能。
- 比如内存泄露:同样,内存泄露在早期可能不会立即耗尽可用内存,因此不会直接影响业务请求的处理。
- 渐进阶段(轻微影响)
- 随着时间的推移,如果CPU持续高负载运行,可能会导致处理能力下降,开始影响到处理请求的速度,出现轻微的延时增加。
- 内存泄露逐渐消耗更多内存,开始影响系统的性能。这可能首先体现为偶尔的性能下降或轻微的延时增加。
- 加速阶段(逐渐增加的影响)
- CPU使用率高:随着系统负载的继续增加,CPU可能无法有效地处理所有请求,导致响应时间显著增加,甚至影响到其他并行运行的服务或应用。
- 内存泄露:内存消耗接近或达到系统上限时,可能导致内存不足,影响到新的请求处理,甚至引发系统的虚拟内存使用,进一步降低系统性能。
- 临界阶段(严重影响)
- 此时,系统可能变得过载,无法有效响应请求,导致大量请求延时显著�增加,错误率上升。
- 在极端情况下,系统可能完全无响应或崩溃,需要重启或其他紧急措施来恢复服务。
- 恢复和分析
- 一旦问题被识别并解决(如优化资源使用、修复内存泄露问题),系统性能会逐渐恢复正常。
- 通过分析导致问题的根本原因和过程,可以采取措施预防未来类似问题的发生。
传统的指标阀值告警模式也许能够在初始阶段就告警,从而为潜在风险提供更多的处理时间,如果告警能够做到精而准确实能够帮助用户争取更多的时间来处理潜在的风险。但是实际情况往往是告警误报过多,从而导致疲劳忽略了告警,别说争取时间了,就是故障已经发展到3或者4阶段的告警都可能被忽略,反而影响了告警的高效处理。
目前 Kindling-OriginX 基于SLO围绕业务告警,针对慢性问题发展成严重故障,基本上做到在3阶段-加速阶段实现告警,这个时候告警完全有时间进行快速处理。未来 Kindling-OriginX 争取发展到2阶段,在早期尽量给用户争取更多的时间来处理潜在的风险。